
助力“新基建” | 这款数据开发神器,帮你提升80%的开发效率
 作者:牧 云袋鼠云产品专家
作者:牧 云袋鼠云产品专家
2017年加入袋鼠云,主导数栈产品从0到1阶段的产品设计,曾负责中金易云、中原银行等多个重点项目交付。
随着数智化时代的到来,企业需要汇聚各业务板块数据,提供一个强大的中间层为高频多变的业务场景提供支撑。基于此类需求,“数据中台”应运而生,将数据提炼为数据资产,转换成业务需要的数据「血液」。
数据中台的建设与运营,通常包含如下活动:数据汇聚、数据加工与提炼、对外提供数据服务这3部分。其中的数据汇聚、数据加工与提炼能力,是由作为数据中台建设基座的离线开发平台提供的。
应用场景例如,某服装企业需要统计最近3个月在全国不同城市中,不同款式的服装的销量情况/库存情况,用于指导下一步的销售活动和款式设计,这些数据需要每天更新,这就是典型的离线计算场景。为了完成上述流程,数据部门需要进行如下处理动作:将最近3个月的销售数据、库存数据从业务系统中抽取出来,要支持每天的增量抽取;结合统计需求,编写SQL进行统计;数据每天更新,需要以天为周期,触发数据抽取、SQL统计的脚本,每天进行数据更新;监控任务的运行情况,当发生异常情况时,需要进行排错、重刷历史数据等操作;为解决以上场景的问题,需要在数据采集、存储、加工等方面进行各种选型对比,通常可归类为以下2类:基于MySQL、Greenplum等关系型或MPP类数据库:o 数据采集:可采用开源的Kettle、DataX等组件,配合shell脚本实现数据抽取;
o 数据开发:本地文本编辑器、Navicat等工具,配合Shell脚本实现数据开发+周期调度;
o 数据运维:人工观察结果数据产出,没有成熟的运维工具,通常都是业务方发现数据问题反馈给技术人员,响应滞后;
o 集群运维:集群监控、告警、扩缩容均手动进行;
基于Hadoop体系的技术方案
o Hadoop体系通常会采用HDFS+YARN作为基座,再配合Hive、Spark、Impala等引擎作为扩展;
o 数据采集、开发、调度,均有多种可选,例如Sqoop、Hue、Oozie/Azkaban/AirFlow等,再配合Shell进行各类组件的打通与配置管理
o 集群运维:可采用开源的Cloudera Manager等工具。
以上2类场景存在以下几种问题:
采集、开发、调度、运维的工具都比较原始,由各种开源组件拼凑组合形成,没有统一高效的管理方式,适用于小规模团队,无法满足大规模、团队协作化的数据中台建设;
在数据采集方面,DataX、Kettle等组件一般都是单点使用,无法满足大吞吐量、高并发的数据同步场景;
在数据开发、任务调度方面,通常只能采用文本编辑器+Navicat+Shell的原始方案,数据开发体验较差,在系统参数、调度打通、函数管理、元数据查看等方面存在各种体验问题;
调度引擎与任务运维方面,开源的Azkaban、AirFlow虽然支持基本的调度逻辑,但与开发环节彼此割裂,没有实现无缝打通。在任务运维方面,只有基本的状态监控,在重刷历史数据、任务异常处理、告警配置等方面均有所欠缺;
在数据管理方面,开源的Hue只有基本的元数据查看,在数据权限、生命周期、元数据扩展等方面均难以满足;
BatchWorks主要功能BatchWorks提供的各项功能,完整覆盖上述场景中的各种需求,包含的功能模块如下:
数据同步:分布式系统架构:基于自研分布式同步引擎(FlinkX),用于在多种异构数据源之间进行数据同步,具有高吞吐量、高稳定性的特点;丰富的数据源支持:支持关系型数据库、半结构化存储、大数据存储、分析性数据库等20余种不同的数据源;可视化配置:主要包括同步任务选择源表、目标表、配置字段映射、配置同步速度等步骤,2分钟即可完成配置;断点续传:系统自动记录每次的同步点位,下一周期运行时,自动从上次的读取位置继续同步,既可以减轻源库的压力,又可以保障同步的数据无遗漏、无重复;整库同步:快速、批量配置大量同步任务,节省大量初始化精力。脏数据管理:在读取、写入阶段发生异常的数据,系统可将这部分数据保存下来,便于用户及时排查脏数据问题。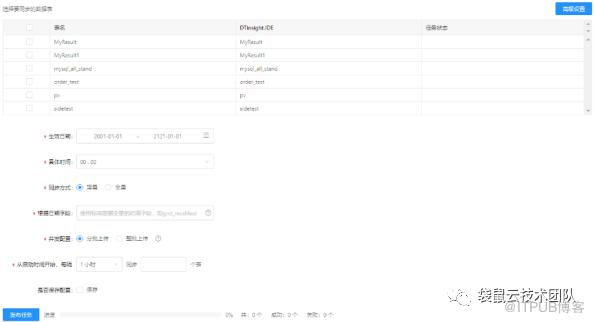 数据开发:丰富的任务类型:支持SparkSQL、HiveSQL、Python、Shell等10余种不同的任务类型,满足不同场景下的数据处理需求;丰富的系统参数:内置多个系统参数,可根据需要指定自定义系统参数,支持常量、变量,可指定丰富的时间格式和时间计算模式;优秀的开发体验:支持代码高亮、关键字/表名/字段名智能提示、语法检测、编辑器主题、快捷键等功能,为用户提供优秀的编码体验;本地文件导入:支持本地csv、txt文件导入至数据表,用于临时性数据分析;函数管理:支持Hive、Spark等计算引擎的函数查看、UDF函数的注册;
数据开发:丰富的任务类型:支持SparkSQL、HiveSQL、Python、Shell等10余种不同的任务类型,满足不同场景下的数据处理需求;丰富的系统参数:内置多个系统参数,可根据需要指定自定义系统参数,支持常量、变量,可指定丰富的时间格式和时间计算模式;优秀的开发体验:支持代码高亮、关键字/表名/字段名智能提示、语法检测、编辑器主题、快捷键等功能,为用户提供优秀的编码体验;本地文件导入:支持本地csv、txt文件导入至数据表,用于临时性数据分析;函数管理:支持Hive、Spark等计算引擎的函数查看、UDF函数的注册;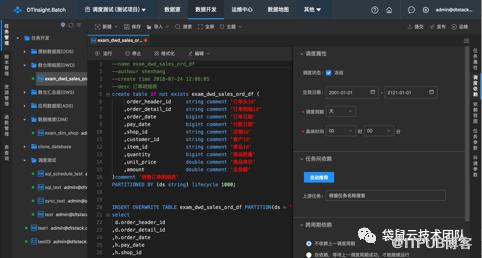 调度引擎:基于自研分布式调度引擎,满足任务的周期性、依赖性调度,支持百万级别任务调度;系统可智能识别当前任务的代码与依赖信息,并自动推荐上游任务;根据用户的调度配置,智能识别超出有效期的任务,自动取消运行,节约计算资源;运维中心:自动监控并统计每日跑批进度、异常情况等信息,汇总易出错任务,协助用户排查代码质量、平台运行情况等问题;实时监控实例运行情况,进行查看日志、重跑、终止、恢复调度等操作;通过指定时间范围,快速重刷历史数据,操作简单、便捷;可根据失败、超时等多种条件触发告警规则,通过短信、邮件等方式将异常信息发送给指定人员;
调度引擎:基于自研分布式调度引擎,满足任务的周期性、依赖性调度,支持百万级别任务调度;系统可智能识别当前任务的代码与依赖信息,并自动推荐上游任务;根据用户的调度配置,智能识别超出有效期的任务,自动取消运行,节约计算资源;运维中心:自动监控并统计每日跑批进度、异常情况等信息,汇总易出错任务,协助用户排查代码质量、平台运行情况等问题;实时监控实例运行情况,进行查看日志、重跑、终止、恢复调度等操作;通过指定时间范围,快速重刷历史数据,操作简单、便捷;可根据失败、超时等多种条件触发告警规则,通过短信、邮件等方式将异常信息发送给指定人员;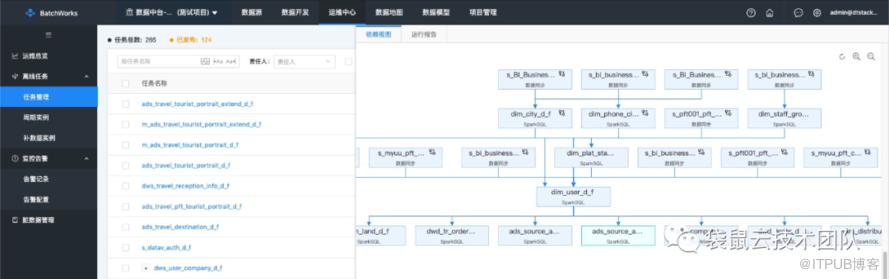 安全保障:BatchWorks采用多种方式保障数据安全和功能操作的安全,主要涵盖集群安全、数据安全和功能安全3部分:集群安全:可对接开源Kerberos组件,保障平台安全访问。数据安全:支持用户跨项目权限申请,可指定需要的具体操作内容和字段信息,经管理员审批通过后可访问。功能安全:内置管理员等多种角色,不同的角色有不同的操作权限,保障功能安全。
安全保障:BatchWorks采用多种方式保障数据安全和功能操作的安全,主要涵盖集群安全、数据安全和功能安全3部分:集群安全:可对接开源Kerberos组件,保障平台安全访问。数据安全:支持用户跨项目权限申请,可指定需要的具体操作内容和字段信息,经管理员审批通过后可访问。功能安全:内置管理员等多种角色,不同的角色有不同的操作权限,保障功能安全。

1.全生命周期覆盖:覆盖数据采集、数据处理、调度依赖、任务运维等场景,充分满足离线数据开发过程中的各项需求,相比传统的开源工具,可以节省80%数据开发时间。
2.多引擎、异构对接:兼容开源、Cloudera、Hortonworks、星环、华为Fusion Insight等各种Hadoop体系或MPP类数据库作为计算引擎;一套离线开发平台支持同时对接多套云环境的异构引擎,例如:一套BatchWorks同时对接阿里云 EMR、AWS EMR、本地机房TiDB引擎;3.自主知识产权:2大核心模块100%自研,掌握全部知识产权
批流一体数据同步引擎FlinkX:基于Flink框架自主研发的分布式、插件化、批流一体数据同步引擎FlinkX,具备全量/增量/实时数据抽取全栈能力。该引擎已经在Github上开源高性能分布式调度引擎DAGScheduleX:自主研发的分布式DAG调度引擎,支持百万级任务并发,具备周期性、依赖性、优先级等多种调度配置4.在线化、可视化操作:产品通过Web页面为用户提供服务,屏蔽底层复杂的分布式计算引擎,在线化开发平台,提高开发效率。
扫一扫,关注我们
