
从PyTorch到PyTorch Lightning —一个简要介绍
【导读】这篇文章回答了关于PyTorch Lightning最常见的问题。
PyTorch很容易使用,可以用来构建复杂的AI模型。但是一旦研究变得复杂,并且将诸如多GPU训练,16位精度和TPU训练之类的东西混在一起,用户很可能会写出有bug的代码。
PyTorch Lightning完全解决了这个问题。Lightning会构建您的PyTorch代码,以便抽象出训练的详细信息。这使得AI研究可扩展并且可以快速迭代。
PyTorch Lightning适合谁使用?
PyTorch Lightning是NYU和FAIR在进行博士研究时创建的
「PyTorch Lightning是为从事AI研究的专业研究人员和博士生所创建的」。
Lightning是在我攻读纽约大学CILVR的人工智能研究和Facebook的AI研究的博士学位中诞生的。该框架被设计为具有极强的可扩展性,同时又使最先进的AI研究技术(例如TPU训练)变得很简单。
现在,核心贡献者都在使用Lightning来推动AI的发展,并继续添加新的炫酷功能。
然而,简单的界面使「专业的生产团队」和「新手」可以使用Pytorch和PyTorch Lightning社区开发的最新技术。
Lightning拥有超过96名贡献者,由8名研究科学家,博士研究生和专业深度学习工程师组成的核心团队。
经过严格测试
并被彻底记录

大纲
本教程将引导您构建一个简单的MNIST分类器,并排显示PyTorch和PyTorch Lightning代码。虽然Lightning可以构建任何任意复杂的系统,但我们使用MNIST来说明如何将PyTorch代码重构为PyTorch Lightning的代码。
完整的代码可在Colab Notebook中获得。
典型的AI研究项目
在一个研究项目中,我们通常希望确定以下关键组成部分:
模型 数据 损失 优化器模型
让我们设计一个三层的全连接神经网络,该网络以28x28的图像作为输入,并输出10个标签的概率分布。
首先,让我们使用PyTorch来定义模型

该模型定义了一个计算图,将MNIST图像作为输入,并将其转换为数字0–9的10个类别的概率分布。
3层网络(由William Falcon所创建)
要将模型转换为PyTorch Lightning,我们只需将nn.Module替换为pl.LightningModule

新的PyTorch Lightning类与PyTorch完全相同,只是LightningModule为研究代码提供了「结构」。
❝Lightning为PyTorch代码提供结构
❞
 看到了吗?这两个代码完全相同!
看到了吗?这两个代码完全相同!
这意味着您可以像使用PyTorch模块「一样」完全使用LightningModule,例如进行「预测」
 或将其用作预训练模型
或将其用作预训练模型
数据
在本教程中,我们使用MNIST数据集。
资料来源:维基百科
让我们将MNIST数据集分成三个部分,即训练,验证和测试部分。
同样地,PyTorch中的代码与Lightning中的代码相同。
数据集被添加到数据加载器中,该数据加载器处理数据集的加载,打乱(shuffling)和批处理。
简而言之,数据准备包括四个步骤:
下载图片。 图像变换(这是由个人而定的)。 拆分成训练集,验证集和测试集。 将每个拆分后的数据集包装在DataLoader中。再次强调,代码与PyTorch「完全相同」,只是我们将PyTorch代码组织为4个函数:
「prepare_data」
此函数进行数据下载和数据处理。此函数可确保当您使用多个GPU时,您不会下载多个数据集或对数据进行双重操作。
这是因为每个GPU将执行相同的PyTorch代码,从而导致重复。所有在Lightning中的代码可以确保关键的部分是「仅由」一个GPU来运行。
「train_dataloader, val_dataloader, test_dataloader」
每一个函数都负责返回对应的数据集。Lightning以这种方式进行构造,因此非常清楚如何操作数据。如果您曾经阅读用PyTorch编写的随机github代码,您几乎看不到它们是如何操纵数据的。
Lightning甚至允许对于测试集或验证集创建多个数据加载器。
优化器
现在,我们决定如何进行优化。我们将使用Adam而不是SGD,因为它在大多数DL研究中都是很好的默认设置。
同样,这两者的代码「完全相同」,只是Lightning把它组织到配置优化器的函数中。
Lightning「可扩展性很强」。例如,如果您想使用多个优化器(例如、GAN),则可以在此处返回两个优化器。
您可能还会注意到,在Lightning中,我们传入了「self.parameters()」,而不是模型,这是因为LightningModule本身就是模型。
损失
对于n分类,我们要计算交叉熵损失。交叉熵与我们将要使用的NegativeLogLikelihood(log_softmax)相同。
 再次强调……代码是完全一样的!
再次强调……代码是完全一样的!
训练和验证循环
我们汇集了进行训练所需要的所有关键要素:
模型(3层的神经网络) 数据集(MNIST) 优化器 损失现在,我们执行一个完整的训练例程,该例程执行以下操作:
迭代多个epoch(一个epoch是对数据集「D」的完整遍历)在数学上
 在代码中
在代码中
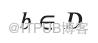
在数学上
在代码中
我们执行前向传播
 在数学上
在数学上
 在代码中
在代码中
在数学上
 在代码中
在代码中
在数学上
在代码中
将梯度应用于每个权重在数学上
在代码中
在PyTorch和Lightning中,伪代码都看起来像这样
但这是PyTorch和Lightning不同的地方。在PyTorch中,您自己编写了for循环,这意味着您必须记住要正确的顺序调用-这为错误留下了很多空间。
即使您的模型很简单,一旦您开始做更高级的事情,例如使用多个GPU,梯度裁剪,提前停止,设置检查点,TPU训练,16位精度等,您的代码复杂性将迅速爆炸。
这是PyTorch和Lightning的验证和训练的循环代码
这就是Lightning代码的美。它抽象化样板代码(不在盒子中的代码),但「其他所有内容保持不变」。这意味着您仍在编写PyTorch,但您的代码结构很好。
这提高了可读性,有助于再现!
Lightning的训练器(Trainer)
训练器(trainer)是我们抽象样板代码的方式。
您要做的就是将PyTorch代码组织到LightningModule中。
PyTorch完整的训练循环的代码
用PyTorch编写的完整MNIST示例如下:
import torch from torch import nn import pytorch_lightning as pl from torch.utils.data import DataLoader, random_split from torch.nn import functional as F from torchvision.datasets import MNIST from torchvision import datasets, transforms import os # ----------------- # 模型 # ----------------- class LightningMNISTClassifier(pl.LightningModule): def __init__(self): super(LightningMNISTClassifier, self).__init__() # MNIST 图片 (1, 28, 28) (channels, width, height) self.layer_1 = torch.nn.Linear(28 * 28, 128) self.layer_2 = torch.nn.Linear(128, 256) self.layer_3 = torch.nn.Linear(256, 10) def forward(self, x): batch_size, channels, width, height = x.sizes() # (b, 1, 28, 28) -> (b, 1*28*28) x = x.view(batch_size, -1) # 第1层 x = self.layer_1(x) x = torch.relu(x) # 第2层 x = self.layer_2(x) x = torch.relu(x) # 第3层 x = self.layer_3(x) # 标签的概率分布 x = torch.log_softmax(x, dim=1) return x # ---------------- # 数据 # ---------------- transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) mnist_train = MNIST(os.getcwd(), train=True, download=True, transform=transform) mnist_test = MNIST(os.getcwd(), train=False, download=True, transform=transform) # 训练集 (55,000 images), 测试 (5,000 images) mnist_train, mnist_val = random_split(mnist_train, [55000, 5000]) mnist_test = MNIST(os.getcwd(), train=False, download=True) # 数据加载器进行shuffling, batching等等的操作。。。 mnist_train = DataLoader(mnist_train, batch_size=64) mnist_val = DataLoader(mnist_val, batch_size=64) mnist_test = DataLoader(mnist_test, batch_size=64) # ---------------- # 优化器 # ---------------- pytorch_model = MNISTClassifier() optimizer = torch.optim.Adam(pytorch_model.parameters(), lr=1e-3) # ---------------- # 损失 # ---------------- def cross_entropy_loss(logits, labels): return F.nll_loss(logits, labels) # ---------------- # 训练循环的代码 # ---------------- num_epochs = 1 for epoch in range(num_epochs): # 训练循环 for train_batch in mnist_train: x, y = train_batch logits = pytorch_model(x) loss = cross_entropy_loss(logits, y) print(train loss: , loss.item()) loss.backward() optimizer.step() optimizer.zero_grad() # 验证循环 with torch.no_grad(): val_loss = [] for val_batch in mnist_val: x, y = val_batch logits = pytorch_model(x) val_loss.append(cross_entropy_loss(logits, y).item()) val_loss = torch.mean(torch.tensor(val_loss)) print(val_loss: , val_loss.item())Lightning完整的训练循环的代码
lightning代码与PyTorch完全相同,除了:
核心成分由LightningModule进行组织 训练/验证循环的代码已由培训器(trainer)抽象化 import torch from torch import nn import pytorch_lightning as pl from torch.utils.data import DataLoader, random_split from torch.nn import functional as F from torchvision.datasets import MNIST from torchvision import datasets, transforms import os class LightningMNISTClassifier(pl.LightningModule): def __init__(self): super(LightningMNISTClassifier, self).__init__() # MNIST 图片 (1, 28, 28) (channels, width, height) self.layer_1 = torch.nn.Linear(28 * 28, 128) self.layer_2 = torch.nn.Linear(128, 256) self.layer_3 = torch.nn.Linear(256, 10) def forward(self, x): batch_size, channels, width, height = x.size() # (b, 1, 28, 28) -> (b, 1*28*28) x = x.view(batch_size, -1) # 第1层 (b, 1*28*28) -> (b, 128) x = self.layer_1(x) x = torch.relu(x) # 第2层 (b, 128) -> (b, 256) x = self.layer_2(x) x = torch.relu(x) # 第3层 (b, 256) -> (b, 10) x = self.layer_3(x) # 标签的概率分布 x = torch.log_softmax(x, dim=1) return x def cross_entropy_loss(self, logits, labels): return F.nll_loss(logits, labels) def training_step(self, train_batch, batch_idx): x, y = train_batch logits = self.forward(x) loss = self.cross_entropy_loss(logits, y) logs = {train_loss: loss} return {loss: loss, log: logs} def validation_step(self, val_batch, batch_idx): x, y = val_batch logits = self.forward(x) loss = self.cross_entropy_loss(logits, y) return {val_loss: loss} def validation_epoch_end(self, outputs): # 在验证结束时调用 # 输出是一个数组,包含在每个batch在验证步骤中返回的结果 # 输出 = [{loss: batch_0_loss}, {loss: batch_1_loss}, ..., {loss: batch_n_loss}] avg_loss = torch.stack([x[val_loss] for x in outputs]).mean() tensorboard_logs = {val_loss: avg_loss} return {avg_val_loss: avg_loss, log: tensorboard_logs} def prepare_data(self): # 图像变换对象 transform=transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 对MNIST进行变换 mnist_train = MNIST(os.getcwd(), train=True, download=True, transform=transform) mnist_test = MNIST(os.getcwd(), train=False, download=True, transform=transform) self.mnist_train, self.mnist_val = random_split(mnist_train, [55000, 5000]) def train_dataloader(self): return DataLoader(self.mnist_train, batch_size=64) def val_dataloader(self): return DataLoader(self.mnist_val, batch_size=64) def test_dataloader(self): return DataLoader(self,mnist_test, batch_size=64) def configure_optimizers(self): optimizer = torch.optim.Adam(self.parameters(), lr=1e-3) return optimizer # 训练 model = LightningMNISTClassifier() trainer = pl.Trainer() trainer.fit(model)强调
让我们指出一些关键点
如果没有Lightning,则可以将PyTorch代码分为任意部分。使用Lightning之后,代码是结构化的。 除了在Lightning中进行结构化之外,这两者的代码完全相同。(这值得大笑两声)。 随着项目的复杂性增加,您的代码将不用改变其中的大部分的代码内容。 保留了PyTorch的灵活性,因为您可以完全控制训练中的关键点。例如,您可以使用任意复杂的training_step,比如seq2seq def training_step(self, batch, batch_idx): x, y = batch # 定义您的前向传播和损失函数 hidden_states = self.encoder(x) # 甚至像seq-2-seq+attn模型一样复杂 # (这只是一个示例代码,用来进行说明的) start_token = <SOS> last_hidden = torch.zeros(...) loss = 0 for step in range(max_seq_len): attn_context = self.attention_nn(hidden_states, start_token) pred = self.decoder(start_token, attn_context, last_hidden) last_hidden = pred pred = self.predict_nn(pred) loss += self.loss(last_hidden, y[step]) #示例代码 loss = loss / max_seq_len return {loss: loss} 在Lightning中,您可以使用很多附加的功能,例如进度条您也得到了漂亮的权重总结

tensorboard日志(是的!您什么都没有做)

和免费的检查点,提前停止。
全部都是自动完成的!
附加功能
Lightning是以开箱即用(例如TPU训练等)而闻名的。
在Lightning中,您可以在CPU,GPU,多个GPU或TPU上训练模型,而无需更改一行PyTorch代码。
https://youtu.be/neuNEcN9FK4
您还可以进行16位精度训练

使用Tensorboard的其他5种替代方法进行记录
使用Neptune.AI进行日志记录(鸣谢:Neptune.ai)
使用Comet.ml记录
我们甚至有一个内置的探查器,可以告诉您在训练中瓶颈的位置。
将此标志设置为on会为您输出
或更高级的输出(如果有需要的话)
我们也可以在多个GPU上进行训练而无需您做任何工作(您仍然必须提交SLURM作业(job))

它支持大约40种其他的功能,您可以在文档中阅读这些功能的使用方法。
带钩子的可扩展性
您可能想知道Lightning是否有可能为您做到这一点,而又以某种方式做到这一点,以便您「完全掌控一切」?
与keras或其他高级框架不同,Lightning不会隐藏任何必要的细节。但是,如果您确实需要自己修改训练的各个方面,那么您有两个主要选择。
第一个选择就是通过覆盖钩子。这是一个详尽的清单:
前向传播 后向传播 应用优化器 进行分布式训练 设置16位精度 如何截断后向传播 … 您需要配置的任何内容这些覆盖发生在LightningModule中
可扩展性的回调
回调是您希望在训练的各个部分中执行的一段代码。在Lightning中,回调用于非必需的代码,例如日志记录或与研究代码无关的东西。这样可以使研究代码保持超级干净和有条理。
假设您想在训练的各个部分进行打印或保存一些内容。这是回调的样子
现在,您将其传递给培训器,该代码将在任意时间被调用
这种方法将您的研究代码组织在三个不同的存储桶(buckets)中
研究代码(LightningModule)(这是科学)。 工程代码(培训器) 与研究无关的代码(回调)如何开始
希望本指南向您确切地介绍了Lightning如何入门。最简单的开始方法是运行带有MNIST示例的colab笔记本。
或安装Lightning
 或查看Github页面。
或查看Github页面。
原文链接:https://towardsdatascience.com/from-pytorch-to-pytorch-lightning-a-gentle-introduction-b371b7caaf09
扫一扫,关注我们
