

-

对MySQL报警的一次分析处理小结
最近有一个服务出现了报警,已经让我到了忍无可忍的地步,报警信息如下: Metric:mysql.innodb_row_lock_waitsTags:port=4306,service=xxxxdiff(#1):996>900 大概的意思是有一个数据库监控指标innodb_row_lock_waits 目前超出了阈值900 但是尴尬的是,每次报警后去环···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-

带你如何从0到1构建一个稳定、高性能的Redis集群
现如今 Redis 变得越来越流行,几乎在很多项目中都要被用到,不知道你在使用 Redis 时,有没有思考过,Redis 到底是如何稳定、高性能地提供服务的? 你也可以尝试回答一下以下这些问题: 我使用 Redis 的场景很简单,只使用单机版 Redis 会有什么问题吗? 我的 Redis 故障宕机了,数据丢失了怎么办?如何能保证我的业务应用不受影响? 为···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-

JeecgBoot 单表数据导出多sheet实例
现在要导出格式如下: 实体如下: publicclassTestEntity{@Excel(name="姓名",width=15)privateStringusername;@Excel(name="年龄",width=15)privateintage;.....省略后续getset 数据格式如下://多个map,对应了多个sheetList<Map···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-
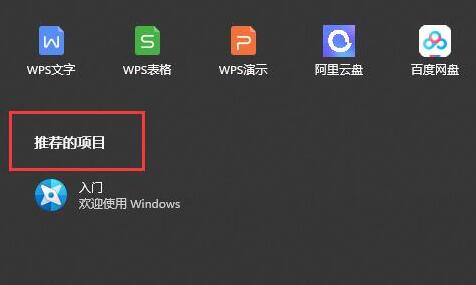
win11推荐的项目详细介绍
在第一次使用win11的时候,我们会发现win11开始菜单不仅ui进行了大调整,还多了一个推荐的项目,这是win10所没有的,那么win11推荐的项目是什么呢,其实就是最近的文件。 win11推荐的项目是什么: 答:win11推荐的项目是最近使用的文件或软件。 它会显示最近打开过的文件和软件,以便再次打开。 而且目前这个功能是无法彻底关闭的,我们只能关闭其···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-

面试官:MySQL中主库跑太快,从库追不上怎么整?
写这篇文章是因为之前有一次删库操作,需要进行批量删除数据,当时没有控制好删除速度,导致产生了主从延迟,出现了一点小事故。 今天我们就来看看为什么会产生主从延迟以及主从延迟如何处理等相关问题。 坐好了,准备发车! - 思维导图 - 主从常见架构 随着日益增长的访问量,单台数据库的应接能力已经捉襟见肘。因此采用主库写数据,从库读数据这种将读写分离开的主从架构便···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-
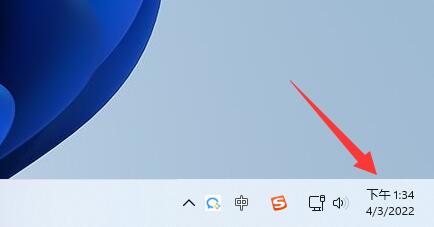
win11通知中心没了解决方法
微软对于win11的通知栏进行了重新制作,并且将它隐藏到了日期列表中,因此如果我们发现win11通知中心没了,可能是因为没有开启通知,也可能是没有找到它。 win11通知中心没了解决方法: 1、首先右键右下角的“时间和日期” 2、接着打开其中的“通知设置” 3、然后在其中打开“通知”开关。 4、开启后,我们只要左键右下角的“时间框” 5、如果有通知,那么在···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-

巧用 Redis pipeline 命令,解决真实的生产问题
本文转载自微信公众号「Java极客技术」,作者鸭血粉丝。转载本文请联系Java极客技术公众号。 Hello,大家好,我是阿粉~ 最近阿粉接到了一个业务需求,需要开发一个业务接口,批量删除 Redis 中数据。 这个功能点其实很简单,只要让外部传入需要删除键信息,然后在接口内部遍历调用删除命令即可。 按照这个思路,功能很快就开发完成,然后顺利的上线。 上线之···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-
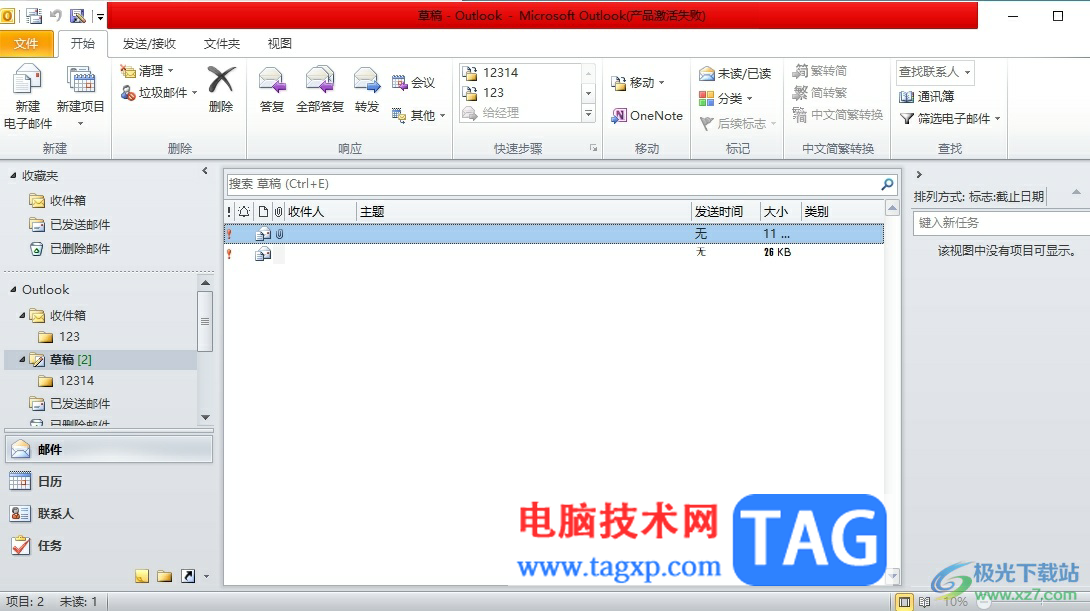
outlook设置成邮件、日历和联系人的默认应用教
outlook是办公软件套装的组件之一,它的功能是很丰富的,用户可以用来收发电子邮件,管理联系人信息、记日记或是安排日程等,能够帮助用户及时处理好重要的工作邮件,当用户在电脑上打开电子邮件时,想要默认在outlook软件中打开,应该怎么来操作实现呢,这个问题需要用户进入到选项窗口中找到常规选项卡,接着选择其中的将outlook设置为电子邮件、联系人和日历的···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-

聊一下Redis持久化RDB和AOF
本文转载自微信公众号「UP技术控」,作者conan5566。转载本文请联系UP技术控公众号。 RDB RDB是Redis内存到硬盘的快照,用于redis持久化,创建RDB二进制文件,将存储在内存中的数据,持久化的放到硬盘中,当我们需要这些数据的时候,启动载入RDB文件,数据将会被存入内存中,其实RDB就是一种快照的方式持久化存储数据,也可以作为一种复制媒介···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
-
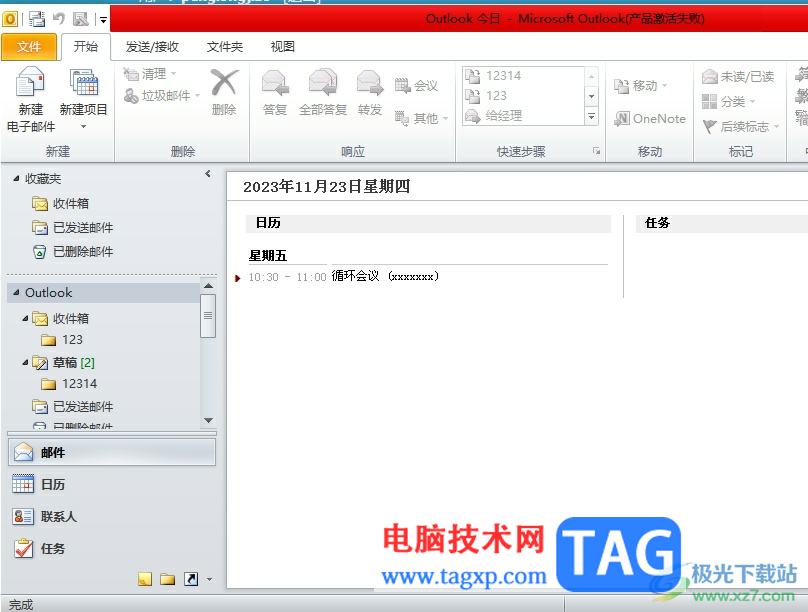
outlook默认答复邮件时附加原件的教程
outlook众所周知是微软办公软件的套装组件之一,它有着丰富的功能,用户可以用来收发电子邮件、管理联系人信息、记日记或是安排日程等,为用户提供了全面的邮件管理和处理服务,因此outlook成为了不少用户的办公必备,当用户在outlook软件在答复他人的邮件时,为了他人知晓回复内容的原邮件信息,用户可以在答复邮件时带上原件,那么用户应该怎么来设置呢,其实操···
- 发布时间:2025-05-15
- 作者:益华网络
- 来源:[list:source]
- 浏览量([list:visits])
- 点赞([list:likes])
【 服务热线 】15368564009
